Reading and Writing Files in NaaVRE
NaaVRE provides three ways to store data. Choosing the right storage is a trade-off between data lifetime and access speed.
| Storage Type | Suitable For... | Lifetime | Speed |
|---|---|---|---|
| Within workflow component storage | Files used in one Jupyter notebook cell / workflow component. | Kept during the execution of the component. | Fastest |
| Between workflow component storage | Passing data between workflow components. | Kept during the workflow run. | Fast |
| Cloud storage | Saving workflow output. | Persistent. | Slower |
Within workflow component storage
This storage is for intermediate files created and used within a single workflow component.
If you use the NaaVRE containerizer to turn a Jupyter cell into a component, files written to the current directory (e.g., ./temp.csv) are private to that step.
They are not accessible to other components and will be deleted once the step finishes.
Keeping data in a variable (in RAM) is always faster than writing to disk. Only write to a file when using it in the same Jupyter cell if your specific tool requires a file path as input.
Between workflow component storage
This storage is meant to pass files between components in a workflow. NaaVRE clears this storage automatically once the workflow finishes. Use this for large intermediate datasets that you don't need to keep once the workflow finishes, as it is faster than cloud storage.
- Path:
/tmp/data/your_file.csv - Guide: The NaaVRE Interface - Managing files in workflows
Cloud storage - Workflow output storage
Use this storage for workflow output, logs, and metadata you want to access after the workflow is done. NaaVRE provides integrated S3-compatible object storage, which has limited capacity and does not create back-ups. You can also provide and integrate with your own external cloud storage.
Integrated Cloud Storage (small/medium files)
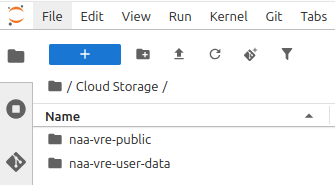
Use the following built-in folders in your file explorer for metadata and small result sets:
- /home/jovyan/Cloud Storage/naa-vre-user-data (Read/Write): Your personal "Cloud Drive."
- /home/jovyan/Cloud Storage/naa-vre-public (Read-Only): You can not write files to this folder, only read from it. It is meant for input datasets and configuration files that all users should be able to use in their workflows.
Python example:
import pandas as pd
dataframe = pd.DataFrame()
dataframe.to_csv("/home/jovyan/Cloud Storage/naa-vre-user-data/dummy_results.csv", index=False)
R example:
write.csv(data.frame(), file = "/home/jovyan/Cloud Storage/naa-vre-user-data/dummy_results.csv")
External Cloud Storage (large datasets)
For "Big Data" (i.e. multiple gigabytes), do not use the integrated folders. Instead, connect directly to external providers.
For example, to read a file from MinIO/S3, in Python you can use the following code:
# Configuration (do not containerize this cell)
param_minio_endpoint = "MINIO_ENDPOINT" # Replace with your MinIO endpoint, e.g., "myhost:9000". The MinIO endpoint for hot storage provided by VLIC is available on request.
param_minio_user_prefix = "myname@gmail.com" # Your personal folder in the naa-vre-user-data bucket in MinIO
secret_minio_access_key = "MINIO_ACCESSKEY" # Replace with your actual MinIO access key
secret_minio_secret_key = "MINIO_SECRETKEY" # Replace with your actual MinIO secret key
# Access MinIO files
from minio import Minio
mc = Minio(endpoint=param_minio_endpoint,
access_key=secret_minio_access_key,
secret_key=secret_minio_secret_key)
# List existing buckets: get a list of all available buckets
mc.list_buckets()
# Download file from bucket: download `myfile.csv` from your personal folder on MinIO and save it locally as `myfile_downloaded.csv`
mc.fget_object(bucket_name="bucket", object_name=f"{param_minio_user_prefix}/myfile.csv", file_path="myfile_downloaded.csv")
# Process file
# For example, read the CSV file using pandas
# Upload file to bucket: uploads `myfile_local.csv` to your personal folder on MinIO as `myfile.csv`
mc.fput_object(bucket_name="bucket", file_path="myfile_local.csv", object_name=f"{param_minio_user_prefix}/myfile.csv")
Similarly, in R you can use the following code:
# Configuration (do not containerize this cell)
param_minio_endpoint = "MINIO_ENDPOINT" # Replace with your MinIO endpoint, e.g., "myhost:9000". The MinIO endpoint for hot storage provided by VLIC is available on request.
param_minio_region = "nl-uvalight"
param_minio_user_prefix = "myname@gmail.com"
secret_minio_access_key = "MINIO_ACCESSKEY"
secret_minio_secret_key = "MINIO_SECRETKEY"
# Access MinIO files
install.packages("aws.s3")
library("aws.s3")
Sys.setenv(
"AWS_S3_ENDPOINT" = param_minio_endpoint,
"AWS_DEFAULT_REGION" = param_minio_region,
"AWS_ACCESS_KEY_ID" = secret_minio_access_key,
"AWS_SECRET_ACCESS_KEY" = secret_minio_secret_key
)
# List existing buckets
bucketlist()
# Download file from MinIO
save_object(
bucket = "bucket",
object = paste0(param_minio_user_prefix, "/myfile.csv"),
file = "myfile_downloaded.csv"
)
# Process file
# For example, read the CSV file using readr
# Upload file to MinIO
put_object(
bucket = "bucket",
file = "myfile_local.csv",
object = paste0(param_minio_user_prefix, "/myfile.csv")
)